| | ||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
|
|
Методы криптоанализа классических шифровА.Г. Ростовцев, Н.В. Михайлова
1.1. Терминология и исходные допущения.Почти общепринятое допущение в криптографии состоит в том, что криптоаналитик противника имеет полный текст криптограммы. Кроме того, криптограф почти всегда руководствуется правилом, впервые сформулированным голландцем Керкхоффом: стойкость шифра должна определяться только секретностью ключа. Иными словами, правило Керкхоффа состоит в том, что весь механизм шифрования, кроме значени секретного ключа, известен криптоаналитику противника. Если криптограф принимает только эти два допущения, то он разрабатывает систему, стойкую при анализе на основе только шифрованного текста. Если к тому же криптограф допускает, что криптоаналитик противника сможет достать несколько отрывков открытого текста и соответствующего ему шифрованного текста, образованного с использованием секретного ключа, то разрабатывается система, стойка при анализе на основе открытого текста. Криптограф может даже допустить, что криптоаналитик противника способен ввести свой открытый текст и получить правильную криптограмму, образованную с использованием секретного ключа (анализ на основе выбранного открытого текста), или предположить, что криптоаналитик противника может подставить фиктивные криптограммы и получить текст, в который они превращаются при расшифровании (анализ на основе выбранного шифртекста), или допустить обе эти возможности (анализ на основе выбранного текста). Разработчики большинства современных шифров обеспечивают их стойкость к анализу на основе выбранного открытого текста даже в том случае, когда предполагается, что криптоаналитик противника сможет прибегнуть к анализу на основе шифртекста. 1.2. Задачи криптографии. Понятие стойкости криптографического алгоритма. Криптология - "особая" область исследований. О достижениях этой науки все чаще сообщают не только научные, но и научно-популярные журналы и обычная пресса. За рубежом в последние годы наблюдается небывалый бум в области криптологии. Это связано с тем, что ее достижения стали применятьс не только в узких ведомственных кругах, но и в жизни миллионов граждан. Широкое внедрение вычислительных систем привело к тому, что они становитс привлекательными для различного рода информационных нападений. Это облегчаетс тем, что информация оказалась лишенной своего физического воплощения, как было ранее (например, текст написан на бумаге и подписан автором). Отсутствие такого физического воплощения, сопряженное с невозможностью аутентификации его автора, открыло путь к различного рода нарушениям. В связи с этим появилась необходимость не только в обеспечении конфиденциальности, но и в обеспечении контроля подлинности и целостности информации. Кроме того, рост ценности информации и информатизация общества ставят вопросы разграничения доступа к информации (например, если пользователь не оплатил работу с базой знаний) и вопросы защиты от компьютерного терроризма. На сегодняшний день така защита осуществляется эффективно с использованием средств криптографии. Системы и средства защиты информации (СЗИ) отличаютс от "обычных" систем
и средств тем, что для них не существует простых и однозначных тестов,
которые позволяют убедиться в том, что информация надежно защищена. Кроме
того, эффективность СЗИ и просто их наличие никак не связываютс на работоспособности
основной системы. Поэтому задача эффективности СЗИ не может быть решена
обычным тестированием. Например, для проверки работоспособности системы
связи достаточно провести ее испытания. Однако успешное завершение этих
испытаний не позволяет сделать вывод о том, что встроенная в нее подсистема
защиты информации тоже работоспособна.
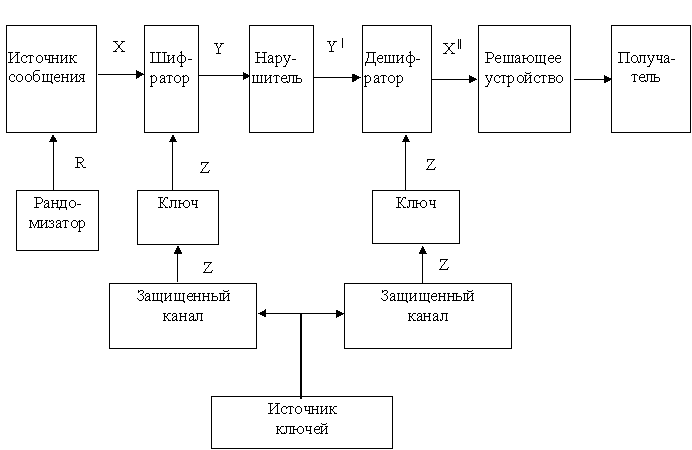
Эти обстоятельства приводят к тому, что на рынке появляется множество средств криптографической защиты информации, про которые никто не может сказать ничего определенного. При этом разработчики держат криптоалгоритм (как показывает практика, часто нестойкий) в секрете. Однако задача точного определения данного криптоалгоритма не может быть гарантированно сложной хотя бы потому, что он известен разработчикам. Кроме того, если нарушитель нашел способ преодоления защиты, то не в его интересах об этом заявлять. В результате, пользователи таких СЗИ попадают в зависимость как минимум от разработчика. Поэтому обществу должно быть выгодно открытое обсуждение безопасности СЗИ массового применения, а сокрытие разработчиками криптоалгоритма должно быть недопустимым. Криптосхемой или криптоалгоритмом будем называть собственно алгоритм шифрования, имитозащиты, и других криптографических функций. Криптографическим протоколом будем называть набор правил и процедур, определяющий использование криптоалгоритма. Криптосистема представляет собой совокупность криптосхемы, протоколов и процедур управления ключами, включая изготовление и распространение. Эти определения не претендуют на строгость и не позволяют провести четкую границу между криптоалгоритмом и протоколом. Так, хэш-функция y = F( z , x ) + x , где F - криптопреобразование с известным ключом z, может рассматриватьс и как самостоятельный криптоалгоритм, и как протокол, использующий преобразование F. Однако для дальнейшего изложения этих определений достаточно. Принято различать криптоалгоритмы по степени доказуемости их безопасности. Существуют безусловно стойкие, доказуемо стойкие и предположительно стойкие криптоалгоритмы. Безопасность безусловно стойких криптоалгоритмов основана на доказанных теоремах о невозможности раскрытия ключа. Примером безусловно стойкого криптоалгоритма являетс система с разовым использованием ключей (шифр Вернама) или система квантовой криптографии, основанная на квантовомеханическом принципе неопределенности. Стойкость доказуемо стойких криптоалгоритмов определяется сложностью решени хорошо известной математической задачи, которую пытались решить многие математики и которая является общепризнанно сложной. Примером могут служить системы Диффи-Хеллмана или Ривеста-Шамира-Адельмана, основанные на сложностях соответственно дискретного логарифмирования и разложения целого числа на множители. Предположительно стойкие криптоалгоритмы основаны на сложности решения частной математической задачи, которая не сводится к хорошо известным задачам и которую пытались решить один или несколько человек. Примерами могут криптоалгоритмы ГОСТ 28147-89, DES, FEAL. К сожалению безусловно стойкие криптосистемы неудобны на практике (системы с разовым использованием ключа требуют большой защищенной памяти для хранения ключей, системы квантовой криптографии требуют волоконно-оптических каналов связи и являются дорогими, кроме того, доказательство их безопасности уходит из области математики в область физики). Достоинством доказуемо стойких алгоритмов являетс хорошая изученность задач, положенных в их основу. Недостатком их являетс невозможность оперативной доработки криптоалгоритмов в случае появлени такой необходимости, то есть жесткость этих криптоалгоритмов. Повышение стойкости может быть достигнуто увеличением размера математической задачи или ее заменой, что, как правило, влечет цепь изменений не только в шифрованной, но и смежной аппаратуре. Предположительно стойкие криптоалгоритмы характеризуютс сравнительно малой изученностью математической задачи, но зато обладают большой гибкостью, что позволяет не отказываться от алгоритмов, в которых обнаружены слабые места, а проводить их доработку. Задача обеспечения защищенной связи включает в себя целый комплекс проблем. Это задача обеспечения секретности и имитозащиты, опознавания (аутентификации) и задача управления ключами, включая их выработку, распределение и доставку пользователям, а также их оперативную замену в случае необходимости. Общая схема организации защищенной связи приведена на рисунке 2.1. Этой же схемой описывается и абонентское шифрование, когда пользователь шифрует информацию, хранимую в памяти ЭВМ. В последнем случае источник сообщений и получатель отождествляется, а канал связи может иметь произвольные задержки.
Источник сообщений вырабатывает произвольную информацию (открытые тексты) с каким-то распределением вероятностей. Шифратор шифрует это сообщение на конфиденциальном (известном только отправителю и получателю) ключе Z и переводит открытый текст в шифрованный текст или шифрограмму (криптограмму, шифртекст). Ключи вырабатываются источником ключей и по безопасным каналам рассылаются абонентом сети связи. Дешифратор раскрывает принятую шифрограмму и передает получателю. В схему на рисунке 2.1. включены еще рандомизатор и решающее устройство. Рандомизатор делает все шифрограммы непохожими друг на друга, даже если входные сообщения одинаковы. Цель этого будет разъяснена ниже. Решающее устройство принимает решение о том, является ли принятое сообщение подлинным, то есть выполняет функцию имитозащиты. Операции шифрования и расшифрования можно описать так: Для взаимной однозначности необходимо, чтобы DE было единичным преобразованием. В этом разделе будет предполагатьс наличие у отправителя и получателя общего секретного ключа Z. (На самом деле ключи у них не обязательно одинаковые, но знание одного ключа, например шифрования, позволяет легко вычислить другой. Поэтому рассматриваемые криптоалгоритмы иногда называют симметричными, или одноключевыми. Соответственно, и криптография, занимающаяся изучением таких алгоритмов, называется одноключевой). Данна схема применяется в том случае, если абоненты сети доверяют друг другу. Ниже показано, как с помощью одноключевой криптографии решаются вопросы имитозащиты и опознавания (секретность обеспечиваетс очевидным образом). Подлинность и целостность сообщения обеспечиваютс его криптографическим преобразованием, выполняемым с помощью секретного ключа. Например, если отправитель передаст сразу и открытый (не требующий засекречивания), и зашифрованный тексты, то это позволит получателю, знающему ключ, утверждать, что текст при передаче по каналу связи не был изменен, если результат расшифрования шифрограммы совпадает с открытым текстом. Действительно, случайное совпадение соответствующих друг другу открытого текста и шифрограммы - практически невозможное событие. Эту пару мог составить лишь отправитель, знающий секретный ключ. Отсюда следует и подлинность сообщения (отправитель отождествляется с владельцем ключа). В действительности нет необходимости передавать всю шифрограмму, достаточно передать лишь ее часть, называемую имитовставкой, которая должна зависеть от всего открытого текста. Тогда получатель может на основании полученного текста и ключа вычислить свою имитовставку и проверить ее соответствие полученной. Для опознавания пользователя используется следующий диалог. Проверяющий вырабатывает случайный текст и посылает опознаваемому для шифрования. Опознаваемый шифрует этот текст и возвращает проверяющему. Тот проверяет соответствие шифрограммы тексту. Правильный ответ может составить только владелец секретного ключа, который отождествляется с законным пользователем. Очевидно, что прослушивающий диалог нарушитель не сможет правильно зашифровать новый текст и назваться пользователем. (Исключением является аналогия известного жульничества, примененного при игре в шахматы по почте, когда нарушитель просто транслирует ответы и запросы подлинным проверяющему и проверяемому, ведя диалог одновременно с каждым из них). Принципиальное отличие данной системы от опознавания по паролю, где подслушивание позволяет узнать секретный пароль и в дальнейшем воспользоваться этим, заключается в том, что здесь по каналу связи секретная информация не передается. Ясно, что и стойкость шифрования, и имитостойкость, и стойкость опознавания могут быть обеспечены, если положенное в основу криптопреобразование является стойким в смысле раскрытия ключа. Криптографические алгоритмы обычно строятся с использованием простых и быстро выполняемых операторов нескольких типов. Множество обратимых операторов, преобразующих текст длиной n бит в текст длинной n бит, являются элементами группы обратимых операторов по умножению (подстановок n-разрядных слов). Пусть f,g,h - обратимые операторы, то есть существуют f -1, g -1 , h -1 . Поэтому hgf - последовательное выполнение операторов f,g,h - тоже обратимый оператор (операторы выполняются справа налево) с обратным оператором к этому произведению f -1, g -1 , h -1 . Поэтому дешифратор выполняет те же операции, что и шифратор, но в обратном порядке, и каждый оператор расшифрования является обратным к соответствующему оператору шифрования. Некоторые операторы являются взаимно обратными, то есть выполнение подряд два раза некоторой операции над текстом дает исходный текст. В терминах теории групп это записывается уравнением f 2 = e , где e - единичный оператор. Такой оператор называется инволюцией. Можно сказать, что инволюция представляет собой корень из единицы. Примером инволюции является сложение по модулю два текста с ключом. Нарушитель может решать следующие задачи. Он может пытаться раскрыть зашифрованную информацию, организовать выборочное пропускание той или иной информации, наконец, он может пытаться изменить подлинную или навязать ложную информацию. Принципиальное различие задач засекречивания и имитозащиты заключается в том, что ключ засекречивани должен быть не доступен нарушителю в течение срока секретности информации, который обычно гораздо больше, чем срок действия ключа и может составлять десятки лет. Ключ имитозащиты представляет интерес для нарушителя только во время его действия. Поэтому и требования к нему предъявляются менее жесткие, чем к ключу засекречивани. Существует еще одно важное применение одноключевой криптографии. Это осуществление вычислимого в одну сторону преобразовани информации. Такое преобразование называется хэш-функцией. Особенность этого преобразования заключается в том, что прямое преобразование y=h(x) вычисляется легко, а обратное x=h-1(y) - трудно. Вообще говоря, обратное преобразование не является функцией, поэтому правильнее говорить о нахождении одного из прообразов для данного значения хэш-функции. В этом случае ключа, понимаемого как некоторая конфиденциальная информация, нет. Однако стойкие хэш-функции, для которых прообраз по данному значению функции тяжело найти, реализуются криптографическими методами и требуют для обоснования стойкости проведения криптографических исследований. Типичное применение хэш-функции - создание сжатого образа для исходного текста такого, что найти другой текст, обладающий таким же образом, вычислительно невозможно. Задача создания стойкой хэш-функции возникает, например, при цифровой подписи текстов. Одно из возможных самостоятельных применений хэш-функций - это опознавание пользователя с помощью цепочки вида Последнее значение цепочки h k(x) является контрольной информацией для проверяющего, а пользователь знает h k-1(x) и предъявляет эту информацию по требованию проверяющего. Проверяющий вычисляет h(h k-1(x)) и сравнивает с контрольной. В следующий раз этот пользователь должен предъявить h k-2(x), а контрольной информацией является h k-1(x) и т.д. Это интересное решение, предложенное А. Конхеймом, однако имеет ряд недостатков. Во-первых, пользователю надо хранить всю цепочку h i(x), что требует большого объема памяти, если число опознаваний может быть велико. Во-вторых, если у каждого пользователя есть несколько проверяющих , то встает вопрос о синхронизации проверяющих по показателям последнего использованного значения h i(x), то есть требуется каналы связи между каждой парой проверяющих. Способность криптосистемы противостоять атакам (активного или пассивного) криптоаналитика называется стойкостью. Количественно стойкость измеряется как сложность наилучшего алгоритма, приводящего криптоаналитика к успеху с приемлемой вероятностью. В зависимости от целей и возможностей криптоаналитика меняется и стойкость. Различают стойкость ключа (сложность раскрытия ключа наилучшим известным алгоритмом), стойкость бесключевого чтения, имитостойкость (сложность навязывания ложной информации наилучшим известным алгоритмом) и вероятность навязывания ложной информации. Это иногда совершенно различные понятия, не связанные между собой. Некоторые криптосистемы, например RSA, позволяют навязывать ложную информацию со сложностью, практически не зависящей от стойкости ключа. Аналогично можно различать стойкость собственно криптоалгоритма, стойкость протокола, стойкость алгоритма генерации и распространения ключей. Уровень стойкости зависит от возможностей криптоаналитика и от пользователя. Так, различают криптоанализ на основе только шифрованного текста, когда криптоаналитик располагает только набором шифрограмм и не знает открытых текстов, и криптоанализ на основе открытого текста, когда криптоаналитик знает и открытие, и соответствующие шифрованные тексты. Поскольку криптоалгоритм обычно должен быть достаточно универсальным, естественным представляется требование, чтобы стойкость ключа не зависела от распределени вероятностей источника сообщений. В общем случае источник сообщений может вырабатывать гудобныеL для нарушителя сообщения, которые могут стать ему известными. В этом случае говорят о криптоанализе на основе специально выбранных открытых текстов. Очевидно, что стойкость ключа по отношению к анализу на основе выбранных текстов не может превышать стойкости по отношению к анализу на основе открытых текстов, а она, в свою очередь, не может превышать стойкости по отношению к анализу на основе шифрованных текстов. Иногда разработчиком СЗИ допускается даже, что враждебный криптоаналитик может иметь доступ к криптосистеме, то есть быть "своим". Обычно криптоалгоритмы разрабатывают так, чтобы они были стойкими по отношению к криптоанализу на основе специально выбранных открытых текстов. Понятие "наилучшего алгоритма" раскрытия ключа в определении стойкости неконструктивно и допускает субъективное толкование (для кого-то из разработчиков наилучшим алгоритмом может быть простой перебор ключей). По-видимому, ни для одного из используемых криптоалгоритмов не определен наилучший алгоритм раскрытия ключа, то есть задача нахождени наилучшего алгоритма является чрезвычайно сложной. Поэтому на практике для оценки стойкости пользуются наилучшим известным или найденным в ходе исследований алгоритмом раскрытия. Таким образом, на практике никто не может помешать способному криптоаналитику снизить оценку стойкости, придумав новый, более эффективный метод анализа. Создание новых эффективных методов раскрыти ключа или иного метода ослабления криптоалгоритма может давать осведомленным лицам большие возможности по нанесению ущерба пользователям, применяющим данный криптоалгоритм. Публикация или замалчивание этих сведений определяютс степенью открытости общества. Рядовой пользователь системы бессилен помешать нарушителю в раскрытии его ключей. Из изложенного следует, что понятие "наилучшего известного" алгоритма неабсолютно: завтра может появиться новый более эффективный алгоритм раскрытия, который приведет к недопустимому снижению стойкости криптоалгоритма. С развитием математики и средств вычислительной техники стойкость криптоалгоритма может только уменьшаться. Для уменьшения возможного ущерба, вызванного несвоевременной заменой криптоалгоритма, потерявшего свою стойкость, желательна периодическая перепроверка стойкости криптоалгоритма. Для снижения вероятности непредсказуемого "обвала" вновь разработанного криптоалгоритма необходимо проведение криптографических исследований. Из рассмотренного выше следует, что понятие стойкости криптосистемы многогранно. Стойкость зависит не только от разработчика, но и от особенностей использования данного криптоалгоритма в системе управлени или связи, от физической реализации криптоалгоритма, а также от будущих успехов математики и вычислительной техники. Ведь криптосистема может эксплуатироватьс много лет, а необходимость сохранять в секрете в течение длительного времени переданную ранее по открытым каналам связи информацию может сделать необходимым прогнозировать развитие науки и техники на десятилети. 1.3. Необходимость криптоанализа.В начале 1970-х гг. была известна только классическая одноключевая криптография, но число открытых работ по этой тематике было весьма скромным. Отсутствие интереса к ней можно объяснить целым рядом причин. Во-первых, острой потребности в криптосистемах коммерческого назначения, по-видимому, еще не ощущалось. Во-вторых, большой объем закрытых исследований по криптографии обескураживал многих ученых, которым, естественно, хотелось получить новые результаты. И наконец, может быть, самый важный фактор заключается в том, что криптоанализ как научная дисциплина фактически по-прежнему представлял собой большой набор разрозненных "трюков", не объединенных стройной математической концепцией. В 1970-х гг. ситуация радикально изменилась. Во-первых, с развитием сетей связи и повсеместным вторжением ЭВМ необходимость в криптографической защите данных стала осознаваться все более широкими слоями общества. Во-вторых, изобретение Диффи и Хелманном криптографии с открытым ключом создало благоприятную почву для удовлетворения коммерческих потребностей в секретности, устранив такой существенный недостаток классической криптографии, как сложность распространения ключей. По существу, это изобретение гальванизировало научное сообщество, открыв качественно новую неисследованную область, которая к тому же обещала возможность широкого внедрения новых результатов быстро развивающейся теории вычислительной сложности для разработки конкретных систем с простым математическим описанием. Ожидалось, что стойкость таких систем будет надежно опираться на неразрешимость в реальном времени многих хорошо известных задач и что, может быть, со временем удастся доказать принципиальную нераскрываемость некоторых криптосистем. Но надежды на достижение доказуемой стойкости посредством сведения задач криптографии к хорошо известным математическим задачам не оправдалась, а, скорее, наоборот. Именно то обстоятельство, что любую задачу отыскани способа раскрытия некоторой конкретной криптосистемы можно переформулировать как привлекательную математическую задачу, при решении которой удаетс использовать многие методы той же теории сложности, теории чисел и алгебры, привело к раскрытию многих криптосистем. На сегодняшний день классическа лента однократного использования остается единственной, безусловно, стойкой системой шифрования. Идеальное доказательство стойкости некоторой криптосистемы с открытым ключом могло бы состоять в доказательстве того факта, что любой алгоритм раскрытия этой системы, обладающий не пренебрежимо малой вероятностью ее раскрытия, связан с неприемлемо большим объемом вычислений. И хотя ни одна из известных систем с открытым ключом не удовлетворяет этому сильному критерию стойкости, ситуацию не следует рассматривать как абсолютно безнадежную. Было разработано много систем, в отношении которых доказано, что их стойкость эквивалентна сложности решения некоторых важных задач, которые почти всеми рассматриваются как крайне сложные, таких, например, как известная задача разложения целых чисел. (Многие из раскрытых криптосистем были получены в результате ослабления этих предположительно стойких систем с целью достижени большого быстродействия.) Кроме того, результаты широких исследований, проводившихся в течение последних десяти лет как в самой криптографии, так и в общей теории вычислительной сложности, позволяют современному криптоаналитику гораздо глубже понять, что же делает его системы нестойкими. Проведение криптоанализа для давно существующих и недавно появившихс криптоалгоритмов очень актуально, так как вовремя можно сказать, что данный криптоалгоритм нестоек, и усовершенствовать его или заменить новым. Дл того, чтобы выявлять нестойкие криптоалгоритмы необходимо все время совершенствовать уже известные методы криптоанализа и находить новые. 2. Обзор известных методов криптоанализа классических шифров .Криптоалгоритм, как правило, должен быть стойким по отношению к криптоанализу на основе выбранных открытых текстов. Первое требование по существу означает, что рассекречивание некоторой информации, передававшейся по каналу связи в зашифрованном виде, не должно приводить к рассекречиванию другой информации, зашифрованной на этом ключе. Второе требование учитывает особенности эксплуатации аппаратуры и допускает некоторые вольности со стороны оператора или лиц, имеющих доступ к формированию засекреченной информации. Криптоанализ может базироваться на использовании как общих математических результатов (например методов разложения больших чисел для раскрытия криптосистемы RSA), так и частных результатов, полученных для конкретного криптоалгоритма. Как правило, алгоритмы криптоанализа являютс вероятностными.
2.1. Типовые методы криптоанализа классических алгоритмов .2.1.1. Метод встречи посередине .Пусть известен открытый текст x и его шифрограмма y. Для текста x строим базу данных, содержащую случайное множество ключей z| и соответствующих шифрограмм w=F(z| , x), и упорядочиваем ее по шифрограммам w. Объем базы данных выбираем О( Ц # {z} ). Затем подбираем случайным образом ключи z| | для расшифровки текстов y и результат расшифровани v = F(z| | , y) сравниваем с базой данных. Если текст v окажется равным одной из шифрограмм w, то ключ z| z| | эквивалентен искомому ключу z. Временная сложность метода составляет О( Ц # {z} log#{z}). Множитель log#{z} учитывает сложность сортировки. Требуемая память равна О( Ц # {z} log#{z}) бит или ОЦ # {z}) блоков ( предполагается, что длина блока и длина ключа различаются на ограниченную константу ). Этот же метод применим, если множество ключей содержит достаточно большое подмножество, являющееся полугруппой. Другое применение этого метода для множества, не являющегося полугруппой, можно продемонстрировать на хэш-функциях. Например, для подделки подписи надо найти два текста, обладающих одним хэш-образом. После этого можно подписанное сообщение заменить на другое, обладающее таким же хэш-образом. Поиск двух таких сообщений можно выполнить с использованием метода "встречи посередине". Сложность поиска равна О(Ц #{h}), где #{h} - число всевозможных хэш-образов. Этот алгоритм является вероятностным. Однако существуют и детерминированный аналог этого алгоритма "giant step - baby step" с такой же сложностью, предложенный американским математиком Д.Шенксом. Этот вероятностный метод основан на следующем факте. Если на некотором конечном множестве М определить случайное отображение f и применить его поочередно ко всем элементам М, а ребрами соответстви - y=f(x) для x,yН М. Поскольку множество М конечно, то этот граф должен содержать деревья, корни которых соединены в циклы. Дл случайного отображения f длина цикла равна О(Ц #М ) и высота дерева в среднем равна О(Ц #М ). Для нахождения ключа, например в криптоалгоритме, основанном на задаче логарифма на некоторой группе, достаточно решить задачу о встрече на графе случайного отображения. Для этого из двух разных стартовых точек x0|, x0| | строятс траектория до входа в цикл. Затем одна из двух конечных точек, лежащих в цикле, фиксируется, а траектория другой продолжается до встречи с фиксированной точкой. Для функции f и точки входа x0 длина траектории составляет О(Ц #М ) шагов. Типичный вид этой траектории содержит предельный цикл длины О(Ц #М ) и отрезок до входа в цикл примерно такой же длины. В качестве индикатора замыкания траектории Поллард предложил использовать равенство xi = x2i , где xi - i-я точка траектории для входа x0. Это равенство будет выполняться всегда. Значение индекса i не превышает суммы длины пути до входа в цикл. В среднем сложность нахождения равенства xi = x2i равна 3Ц (p /8)#М. Сложность встречи, когда обе точки лежат в цикле, равна 0,5Ц (p /8)#М. Таким образом, итоговая сложность равна 6,5Ц (p /8)#М. Метод Полларда применяется для решения задачи логарифма на циклической группе, поиска частично эквивалентных ключей (коллизий), для нахождения двух аргументов, дающих одинаковое значение хэш-функции, и в некоторых других случаях. Применительно к задаче логарифмирования этот метод позволяет отказаться от использования большого объема памяти по сравнению с методом встречи посередине. Кроме того, пропадает необходимость сортировки базы данных. В результате временная сложность по сравнению с методом встречи посередине снижается на множитель О(log#М). Сложность этого метода в данном случае составляет О(Ц #М ) шагов и требует памяти объема О(1) блоков. Однако не всегда требуетс малая память.
Рассмотрим в качестве иллюстрации метода Полларда алгоритм нахождения коллизии (двух аргументов, дающих одинаковое значение хэш-функции) для вычислительной модели с объемом памяти О(v). Такими аргументами будут элементы множества М, стрелки от которых под действием хэш-функции f ведут в точку входа в цикл. Практически алгоритм сводится к нахождению точки входа в цикл. 1. Войти в цикл, используя равенство xi = x2i = t . 2. Измерить длину цикла m, применяя последовательно отображение f к элементу t до получения равенства fm(t)=t . 3. Разбить цикл m на v интервалов одинаковой или близкой длины и создать базу данных, запомнив и упорядочив начальные точки интервалов. 4. Для стартовой вершины п.1 выполнять одиночные шаги до встречи с какой-либо точкой из базы данных п.3. Отметить начальную и конечную точки интервала, на котором произошла встреча. 5. Стереть предыдущую и создать новую базу данных из v точек, разбив интервал, на котором произошла встреча, на равные по длине части, запомнив и отсортировав начальные точки интервалов. 6. Повторить процедуры пп.4,5 до тех пор, пока не получится длина интервала, равная 1. Вычислить точку встречи в цикле, вычислить коллизию как пару вершин, одна из которых лежит в цикле, а друга - нет. Этот алгоритм требует многократного выполнени О( Ц #М ) шагов до входа в цикл и выполнени сортировки базы данных. На каждом этапе при создании новой базы данных длина интервала сокращается в v раз, то есть количество повторов равно О( logv #М ). Если v << Ц #М, то сложностью сортировки базы данных можно пренебречь. Тогда сложность алгоритма равна О(Ц #М logv #М). Рассмотрим возможность улучшения оценки сложности этого метода за счет увеличения доступной памяти. Напомним, что почти все вершины графа случайного отображения лежат на одном дереве. Поэтому будем решать задачу о встрече на случайном ориентированном дереве. С ростом глубины h ширина дерева b(h) уменьшается, то есть случайное отображение обладает сжимающими свойствами. Поэтому с ростом глубины вершины, с одной стороны, увеличивается сложность встречи за счет многократного применения отображения, с другой стороны, увеличивается вероятность встречи в силу сжимающих свойств. Доля вершин с глубиной не менее h равна О(1/h). Рассмотрим два алгоритма для решения задачи о встрече. Первый алгоритм предусматривает выбор множества m случайных начальных вершин, применение к ним к раз отображения, сортировку множества конечных вершин и поиск среди них равных. Второй алгоритм предусматривает запоминание всей траектории спуска для каждой вершины, сортировку множества вершин, составляющих траектории, и поиск среди равных. Второй алгоритм являетс не менее сложным, чем первый, в силу сжимающих свойств случайного отображения. Сложность первого алгоритма равна km (log m). Множитель log m учитывает сложность сортировки. В силу парадокса дней рождения m = О(#M/h)0.5. Для одного шага сложность алгоритма равна О(Ц #M log#M), то есть этот алгоритм более эффективный, чем алгоритм встречи посередине. После первого шага от листа глубины становитс равной О( log#М ). Однако в дальнейшем рост глубины с каждым шагом замедляется. Это объясняется существенно разрывным характером условной вероятности р(h|H) получения глубины h при исходной глубине H. Действительно, из определения глубины следует, что каждая вершина с глубиной H+1 связана ребром с вершиной с глубиной H. Из каждой вершины исходит единственное ребро. Поэтому в силу количественных оценок ширины графа Числитель этого выражения равен разности ширины графа на глубинах H и H+1, знаменатель учитывает то, что исходная глубина равна Н. Вероятность попасть на глубину h>H+1 определяется вероятностью непопадания на глубину H+1 и шириной графа, Сравним вероятность pk(h) получени глубины h после k шагов при спуске от листа и вероятность pk(h|Mk-1) глубины h после k шагов при условии, что на шаге k-1 глубина равнялась математическому ожиданию. Имеет место оценка pk(h)ё pk(h|Mk-1). Поэтому место вероятности сложного события pk(h) можно рассматривать вероятность простого события pk(h|Mk-1). Пусть стартовая вершина лежит на глубине H=O( log#M). Какова будет глубина после очередного шага? Непосредственные вычисления показывают, что математическое ожидание глубины равно H+1+O(1), то есть второй и последующий шаги увеличивают глубину спуска на О(1). Подстановка в качестве исходной глубины математического ожидания глубины спуска на предыдущем шаге дает оценку математического ожидания глубины спуска после к шагов : Поскольку оптимальное число шагов при спуске к алгоритма определяется равенством сложности спуска mk и сложности сортировки m log m, то копт=O(log#M). Отсюда следует, что задача встречи на случайном ориентированном дереве не менее сложна, чем задача о встрече в цикле, то есть алгоритм Полларда не улучшаем за счет увеличения доступной памяти. Дифференциальный метод криптоанализа (ДКА) был предложен Э.Бихамом и А.Шамиром в 1990 г. Дифференциальный криптоанализ - это попытка вскрытия секретного ключа блочных шифров, которые основаны на повторном применении криптографически слабой цифровой операции шифровани r раз. При анализе предполагается, что на каждом цикле используется свой подключ шифрования. ДКА может использовать как выбранные, так и известные открытые тексты . Успех таких попыток вскрытия r-циклического шифра зависит от существования дифференциалов (r-1)-го цикла, которые имеют большую вероятность. Дифференциал i-го цикла определяется как пара ( a , b )i такая, что пара различных открытых текстов x, x* c разностью a может привести к паре выходных текстов y, y* после i-ого цикла, имеющих разность b (дл соответствующего понятия разности ). Вероятность i-циклового дифференциала (a ,b )i - это условная вероятность P(D y(i)=b | D x= a ) того, что разность D y(i) пары шифротекстов ( y, y*) после i-ого цикла равна b при условии, что пара текстов (x, x*) имеет разность D x=a ; открытый текст x и подключи циклов к(1) , к(2) ,...., к(i) независимыми и равновероятными. Основная процедура ДКА r- циклического шифра с использованием выбранных открытых текстов может быть следующей : 1. На этапе предвычислений ищем множество (r-1)-цикловых дифференциалов (a 1,b 1)r-1 , (a 2,b 2)r-1 ,.... (a s,b s)r-1 . Упорядочиваем это множество дифференциалов по величине их вероятности. 2. Выбираем открытый текст x произвольным образом
и вычисляем x* так, чтобы разность между x и x* была равна a
1. Тексты
3. Повторяем п.2 до тех пор, пока одно или несколько значений подключа к(r) не станет появляться чаще других. Берем этот подключ или множество таких подключей в качестве криптографического решения для подключа к(r). 4. Повторяем пп.1-3 для предпоследнего цикла, при этом значения y(r-1) вычисляются расшифрованием шифртекстов на найденном подключе последнего цикла к(r). Далее действуем аналогично, пока не будут раскрыты ключи всех циклов шифрования. Предложенный впервые для анализа конкретного шифра, ДКА оказался применимым для анализа широкого класса марковских шифров. Марковским называется шифр, у которого уравнение шифрования на одном цикле удовлетворяет условию: вероятность дифференциала не зависит от выбора открытых текстов. Тогда, если подключи циклов независимы, то последовательность разностей после каждого цикла образует марковскую цепь, где последующее состояние определяется только предыдущим. Примерами марковских шифров являютс DES и FEAL . Можно показать, что марковский r-цикловый шифр с независимыми подключами является уязвимым для ДКА тогда и только тогда, когда для одного цикла шифрования ключ по известной тройке (y,y*,D x) может быть легко вычислен, и существует (r-1)-цикловый дифференциал (a ,b )к-1 такой, что его вероятность удовлетворяет условию где n-количество бит в блоке шифруемого текста. Сложность раскрытия ключа r-циклического шифра Q(r) определяется как число используемых шифрований с последующим вычислением ключа: где Pmax=max(a )max(b )(P(D y(r-1)=b | D x=a )). В частности, если Pmax ё 1/(2n-1), то атака не будет успешной. Поскольку вычисление подключа - более трудоемкая операция, чем шифрование, то единицей измерения сложности является сложность нахождения возможных подключей одного цикла по известным (D y(r-1),y(r),y*(r)). Отличительной чертой дифференциального анализа является то, что он практически не использует алгебраические свойства шифра (линейность, аффинность, транзитивность, замкнутость и т.п.), а основан лишь на неравномерности распределения вероятности дифференциалов. 2.1.4. Линейный метод криптоанализа .Обычно при шифровании используется сложение по модулю 2 текста с ключом и операции рассеивания и перемешивания. Задача криптоаналитика - найти наилучшую линейную аппроксимацию (после всех циклов шифрования ) выражения Пусть pL - вероятность того, что (3.1) выполняется, при этом необходимо, чтобы pL - 1/2 и величина | pL-1/2 | должна быть максимальна. Если | pL-1/2 | достаточно велика и криптоаналитику известно достаточное число пар открытых и соответствующих зашифрованных текстов, то сумма по модулю 2 бит ключа на соответствующей позиции в правой части (3.1) равна наиболее вероятному значению суммы по модулю 2 соответствующих бит открытых и зашифрованных текстов в левой части. Если pL > 1/2, то сумма бит ключа в правой части (3.1) равна нулю, если сумма бит в левой части равна нулю больше, чем для половины пар зашифрованных текстов, и сумма бит ключа в правой части (3.1) равна единице, если сумма бит в левой части равна единице больше, чем для половины текстов . Если pL< 1/2 , то наоборот : сумма бит ключа в правой части (3.1) равна нулю , если сумма бит в левой части равна единице больше , чем для половины пар открытых и зашифрованных текстов, и сумма бит ключа в правой части (3.1) равна единице, если сумма бит в левой части равна нулю больше, чем для половины текстов. Для нахождени каждого бита собственно ключа теперь нужно решить систему линейных уравнений для известных линейных комбинаций этих бит, но эта процедура не представляет сложности, так как сложность решения системы линейных уравнений описываетс полиномом не более третьей степени от длины ключа. Требуемое для раскрытия ключа количество N пар открытых и зашифрованных текстов (блоков) оценивается выражением Для раскрытия ключа шифра DES этим методом необходимо 247 пар известных открытых и зашифрованных текстов. Для анализа шифров могут использоваться различные математические инструменты. Однако существуют общие принципы решения сложных вычислительных задач . Обычно задачу вычисления ключа можно переформулировать как задачу поиска внутри большого конечного множества М элемента m, обладающего нужными свойствами. Один из подходов к решению этой задачи получил название гразделяй и властвуйL. Суть его заключается в том, что исходная сложна задача поиска разделяется на две подзадачи. Для этого множество элементов разбивается на пересекающиеся или слабо пересекающиеся перечислимые подмножества, распознаваемые по отношению к свойствам, которыми обладает данный элемент. На первом этапе ищется подмножество, в котором находится требуемый элемент (решается первая подзадача), затем ищется требуемый элемент внутри найденного подмножества(решается вторая подзадача). Такого рода разбиение может применятьс многократно. Примером такого подхода является известный способ угадывани произвольного слова из многотомной энциклопедии, если отгадывающий может задать 20 вопросов и получать на них ответы гдаL или гнетL. Подход гразделяй и властвуйL может быть использован и при проведении анализа шифров. Естественно, его применение должно быть индивидуальным для каждого криптоалгоритма. Например, если множество М допускает разбиение на подмножества, распознаваемые в части свойства А, и существует сжимающее отображение, действующее на этих подмножествах и сохраняющее данное свойство А, то метод Полларда может быть применен не к элементам множества М, а к подмножествам, содержащим данный элемент. Другой эффективный метод решения вычислительных задач заключается в том, что множество М упорядочивается в порядке убывани вероятности того, что данный элемент обладает нужным свойством. Далее происходит опробование элементов М (перебор), начиная с наиболее вероятных. Это техника использована в дифференциальном методе анализа. Если вероятности распределены существенно неравномерно, то получается большой выигрыш по сложности. В частности, если вероятности образуют геометрическую прогрессию, то сложность нахождения нужного элемента оказывается линейной от размера задачи (логарифма мощности исходного множества). Общепринятым инструментом является также линеаризаци задачи. Это часто обусловлено тем, что аффинные аппроксимации преобразований образуют полугруппу относительно композиции и имеют простые описания. Однако такую полугруппу образуют не только аффинные преобразования, но и другие объекты, например симметрические полиномы, решетки, некоторые классы форм (однородных полиномов, все слагаемые которых имеют одинаковую степень ). Под композицией полиномов понимается подстановка полинома в качестве переменной в другой полином. Андельман и Ридс для анализа шифров предложили использовать переход от исходного дискретного шифратора к гнепрерывномуL шифратору, который совпадает с исходным на вершинах n-мерного единичного куба, и далее искать непрерывный ключ с использованием техники поиска экстремумов непрерывных отображений. Заметим, что здесь кроется определенная сложность . Это вызвано тем, что все элементы кольца полиномов Жегалкина или кольца булевых функций с операциями И, ИЛИ, НЕ является идемпотентными. Пусть переменные принимают значения из некоторого непрерывного подмножества А вещественных чисел. Для численных значений вещественных аналогов булевых формул необходимо обеспечить x2=x, для любого рационального числа r. Таким образом, все вещественные числа А оказываются равными, то есть элементы А являются элементами факторгруппы R/Q. Нетрудно видеть, что ни в одной вычислительной модели с конечной разрядностью числа из А непредставимы, поэтому такой метод не работает ( по крайней мере, для вещественных и, следовательно, для комплексных чисел ). Каждый новый метод криптоанализа приводит к пересмотру безопасности шифров, к которым он применим. Если целью криптоаналитика является раскрытие возможно большего числа шифров ( независимо от того, хочет ли он этим нанести ущерб обществу, предупредить его о возможной опасности или просто получить известность), то для него наилучшей стратегией являетс разработка универсальных методов анализа. Но эта задача является также и наиболее сложной. Алгоритмы (стандарты) шифрования периодически меняются (что видно на примере шифров LUCIFER, DES, FEAL, клиппер-чипов), а секретная информация часто имеет свойство стареть, то есть не представляет большого интереса для нарушителя спустя какое-то время после ее передачи по каналам связи в зашифрованном виде. Поэтому зависимость эффекта от нахождени способа раскрытия ключей данного шифра во времени имеет максимум: в начале срока своего действия криптоалгоритм не имеет широкого распространения, а в конце срока он перестает быть популярным, а основной объем зашифрованной информации не представляет интереса. |